Source documentation
vt_server
This is a Voice Transformation server. It receives command stacks as JSON arrays to process sound files that are local on the server, and returns a pointer to the processed file.
- class vt_server.VTHandler(request, client_address, server)
Bases:
StreamRequestHandlerThe handler for the server requests.
Requests are JSON encoded. It is required that they contain the following field action which can receive one of two values: “status” or “process”.
If action is “status”, then no other field is required.
If action is “process”, then the following fields are required:
- file
The sound file(s) that will be processed. This can also be an array of files or of queries. The stack is applied to the concatenated result. The file path is relative to where the server is running from (not the client). It is highly recommended to use absolute paths instead of relative paths. Also note that the input sound files should be in a format understood by linsndfile.
Note: In version 2.2 it was possible to use “ >> “ to separate files. This has been removed in 2.3. Support for subqueries as file has been added in 2.3.
- stack
The list of processes that will be run on the file. Each item in the stack is an object that is specific to the type of processing. Each object must have a module attribute that is used to dispatch the processing. This can also be a list of stacks that apply to everyone of the files if file is an array (otherwise, the same stack is applied to all files before concatenation).
The following fields are optional:
- mode
“sync” [default], “async” or “hash”. In sync mode, the server will only send a response when the file is processed. In async mode, the server will respond immediately with a “wait” response. The client can probe periodically with the same request until the file is returned. hash only returns the hash of the request that is used as identifier.
- format
Specifies the output format of the sound files. Can be “flac”, “wav” (or anything else supported by libsndfile, or “mp3” (if LAME is installed). If none is provided, then the default cache format is used (see
vt_server_config).- format_options
Specifies options (as a dictionary) for the selected format. At the moment, only bitrate is specified (as an integer in kbps) for format “mp3” (see
vt_server_brain.encode_to_format()for details).- cache
This defines when the cache will expire. Cache files are deleted either when one of the source files is missing, or when the cache expires. The cache expiration date is updated everytime the file is requested. If True or None (null in JSON), no expiration is set for the cache file. If False, the cache is set to expire after 1h. Otherwise a duration before expiration can be provided in hours. Keep in mind that the generated sound file has to exist long enough for it to be downloaded by the client. Note that sub-queries do not inherit cache status from their parents. If not provided, the cache value is 730, which corresponds roughly to 1 month.
The response is also JSON and has the following form:
- out
“ok”, “error”, or “wait”
- details
In case of success, this contains the outcome of the processing. In case of error, this has some details about the error.
- handle()
The handler function. It basically receives the query in JSON, tries to parse it and then dispatch to
vt_server_brain.process()if it worked. Then sends the response back to the client.
- class vt_server.VTServer(server_address, RequestHandlerClass, bind_and_activate=True)
Bases:
ThreadingTCPServer- server_activate()
Called by constructor to activate the server.
May be overridden.
- server_close()
Called to clean-up the server.
May be overridden.
- vt_server.main()
Imports the configuration, instantiates a
VTServerand starts thevt_server_brain.Janitorbefore starting the server itself.Runs forever until the server receives SIGINT.
vt_server_brain
Dispatches the processing to the right underlings. The brain also manages the various processes and the main cache. Each request is dispatched to its own process as a job.
Jobs have a signature that is based on the task at hand:
the file it applies to,
and the process instruction stack list.
These are serialized (using pickle) and then hashed (in md5) to create the job signature. The job signature is also used for the name of the cache file.
Everytime a job is submitted, the brain first checks if the file already exists.
If the file exists, it is returned right away. If the file does not exist, then
we check if the job is in the JOBS list (a managed dictionary). If it is in
the list, then we just reply ‘wait’ to the client. If not, then the brain
creates the job and starts the process.
In ‘sync’ mode, the dispatcher waits for the process to be completed.
In ‘async’ mode (default) it returns right away and sends a ‘wait’ message. The client can send the same request a bit later. If the job is still being processed, the server sends the same ‘wait’ response. If the job is completed, then the job target file exists and is returned right away.
Individual tasks listed in the task list can have their own cache system, but they need to manage it themselves.
A Janitor is scouring the JOBS list to check on jobs that may be finished,
and remove them from the list.
- vt_server_brain.JOBS = <DictProxy object, typeid 'dict'>
This is the list of current jobs (actually a managed dict).
- class vt_server_brain.Janitor(interval)
Bases:
objectThe janitor periodically checks the job list to see if there are any finished jobs, and then gets rid of them.
- call_repeatedly(interval)
- static janitor_job()
Checks periodically on the
JOBSlist to see if there are any process that is finished and needs removing.
- kill()
- class vt_server_brain.QueryInType(*values)
Bases:
IntEnum- FILE = 0
- GENERATOR = 2
- LIST = 3
- QUERY = 1
- vt_server_brain.cast_outfile(f, out_filename, req, h)
- vt_server_brain.encode_to_format(in_filename, out_filename, fmt, fmt_options)
Encodes the file to the required format. This is for formats that are not supported by libsndfile (yet), like mp3.
- vt_server_brain.job_signature(req)
- vt_server_brain.multi_process_async(req, h, out_filename)
- vt_server_brain.process(req, force_sync=False)
Creates jobs (populating the
JOBSlist), checks on cache and dispatches processing threads.- Parameters:
req (dict) – The query received by the server.
- vt_server_brain.process_async(req, h, out_filename)
This is the function that is threaded to run the core of the module. It dispatches calls to the appropriate modules, and deals with their cache.
It also updates the
JOBlist when a job is finished, and create a job file with some information about the job (useful for cache cleaning).If a module takes a ‘file’ as argument, the file can be a query. It will be executed in sync mode from the current
process_async()process.Job files are pickled dict objects that contain the following fields:
- original_file [string]
The original sound file that the job was based on.
- created_files [list]
The list of files that were created in the process. This includes the final sound file, but also intermediate files that may have been necessary to the process.
- used_files [list]
If an intermediate file was used, but not created by the current job, it is listed here.
- stack [dict]
The stack that defines the job.
- cache_expiration [tuple(datetime, float)] optional
If None or missing, the cache does not expire by itself. Otherwise, the field contains a date after which the created_files can be removed, and a time-delta in hours. Everytime the file is accessed, the cache expiration is updated with the time-delta.
- vt_server_brain.process_module(f, m, format, cache=None)
Applying a single module and managing the job-file.
- Parameters:
f – The source file (string) or sub-query (dict).
m – The module parameters.
format – The file format the sound needs to be generated into.
cache – The cache expiration policy (either None, by default, or a tuple with a date and a number of hours).
vt_server_common_tools
This module contains function that may be useful across other VTServer modules.
- vt_server_common_tools.clipping_prevention(x)
- vt_server_common_tools.job_file(target_file, source_files, cache_expiration=None, stack=None, error=None)
Creates a job file for the target_file specified.
- Parameters:
target_file – The output file that this job file concerns.
source_files – The list of source files that were used to produce the target file. During cache clean-up, if one of the source files is removed, the target will be removed.
cache_expiration – A tuple with the cache expiration datetime and the duration of validity in hours, or None (default if omitted).
stack – Optionnally a stack can be provided. None otherwise.
- vt_server_common_tools.ramp(x, fs, dur, shape='cosine')
The underlying function to the “ramp” processing module.
- Parameters:
x – The input sound.
fs – The sampling frequency.
dur – The duration of the ramps (a two-element iterable).
shape – The shape of the ramp (‘cosine’ or ‘linear’). Defaults to ‘cosine’.
- Returns:
The ramped sound.
- vt_server_common_tools.resample(x, ratio, method=None)
The common resampling function.
Each module can use their own resampling function, but this one will default to the best available option. If samplerate is installed, it will be used. Otherwise, the
scipy.signal.resample()function is used.- Parameters:
x – The input sound as a numpy array.
ratio – The ratio of new frequency / old frequency.
method – ‘scipy’, ‘samplerate’, ‘samplerate-fast’. Defaults to ‘samplerate’ if the module is available, and ‘scipy’ otherwise.
- vt_server_common_tools.rms(x)
- vt_server_common_tools.signature(desc)
- vt_server_common_tools.update_job_file(target_file)
Updates the target_file cache expiration date if necessary. Note that target_file is not the job file itself, but the file targeted by the job-file.
vt_server_modules
This module contains a number of process_... functions, imports
the other process modules and defines the MODULES patch that dispatches
process module names to the right process function.
There are two types of modules:
- ‘modifier’
The modules take a source sound file as input and generate a new sound file from it. The cache management for these modules is such that, before the cache expiration date, if a source sound file is missing, the generated file will also be removed. Source files are listed in the job-files. After the expiration date, the generated file is removed.
- ‘generator’
These modules do not take a source sound file as input, but generate sounds via other means. Sometimes they do need source files and therefore need to declare themselves which files they have used.
- vt_server_modules.MODULES = {'channel-patch': <vt_server_modules.vt_module object>, 'mixin': <vt_server_modules.vt_module object>, 'pad': <vt_server_modules.vt_module object>, 'ramp': <vt_server_modules.vt_module object>, 'slice': <vt_server_modules.vt_module object>, 'time-reverse': <vt_server_modules.vt_module object>}
The
MODULEis used to dispatch stack item modules to their corresponding function
- vt_server_modules.discover_modules()
- vt_server_modules.process_channel_patch(in_filename, m, out_filename)
“channel-patch” copies the input signal onto various channels. The arguments are:
- coefs
An array of coefficients applied to each channel. If the input signal is X, and the coefficients are [a1, a2], the output will be [a1⋅X, a2⋅X]. In a two-channel (stereo) file, the first channel is the left channel, and the second channel is the right channel.
- vt_server_modules.process_mixin(in_filename, m, out_filename)
“mixin” adds another sound file (B) to the input file (A). The arguments are:
- file
The file that needs to be added to the input file.
- levels =[0,0]
A 2-element array containing the gains in dB applied to the A and B.
- pad =[0,0,0,0]
A 4-element array that specifies the before and after padding of A and B (in seconds):
[A.before, A.after, B.before, B.after]. Note that this could also be done with sub-queries, but doing it here will reduce the number of cache files generated.- align =’left’
‘left’, ‘center’, or ‘right’. When the two sounds files are not the same length, the shorter one will be padded so as to be aligned as described with the other one. This is applied after padding.
If the two sound files are not of the same sampling frequency, they are resampled to the max of the two.
If the two sound files are not the same shape (number of channels), the one with fewer channels is duplicated to have the same number of channels as the one with the most.
- vt_server_modules.process_pad(in_filename, m, out_filename)
“pad” adds silence before and/or after the sound. It takes before and/or after as arguments, specifying the duration of silence in seconds.
- vt_server_modules.process_ramp(in_filename, m, out_filename)
“ramp” smoothes the onset and/or offset of a signal by applying a ramp. The parameters are:
- duration
In seconds. If a single number, it is applied to both onset and offset. If a vector is given, then it specifies [onset, offset]. A value of zero means no ramp.
- shape
Either ‘linear’ (default) or ‘cosine’.
- vt_server_modules.process_slice(in_filename, m, out_filename)
“slice” selects a portion of a sound. It takes the following arguments:
- start
The onset point, in seconds. [0 if omitted.]
- end
The offset point, in seconds. Negative number are counted from the end. Values exceding the length of the file will lead to zero padding. [The end of the sound if omitted.]
If the start time is larger than the end time, an error is raised.
- vt_server_modules.process_time_reverse(in_filename, m, out_filename)
“time-reverse” flips temporally the input. It doesn’t take any argument.
- class vt_server_modules.vt_module(process_function, name=None, type='modifier')
Bases:
objectThis class is a simple wrapper for the module functions.
- Parameters:
process_function – The main process function of the module.
name – The name of the module, which is also the keyword used in queries. If
None, the name is derived from the process_function name.type – The type of module (‘modifier’ or ‘generator’).
To access the name of the module, use the attribute :py:attr:__name__.
To call the process function, you can use the class instance as a callable.
vt_server_module_world
This module defines the world processor based on pyworld, a module wrapping Morise’s WORLD vocoder.
Here are some examples of module instructions:
{
"module": "world",
"f0": "*2",
"vtl": "-3.8st"
}
If a key is missing (here, duration) it is considered as None, which means this part is left unchanged.
f0 can take the following forms:
*followed by a number, in which case it is multiplicating ratio applied to the whole f0 contour. For instance*2.a positive or negative number followed by a unit (
Hzorst). This will behave like an offset, adding so many Hertz or so many semitones to the f0 contour.
~followed by a number, followed by a unit (onlyHz). This will set the average f0 to the defined value.
vtl is defined similarly:
*represents a multiplier for the vocal-tract length. Beware, this is not a multiplier for the spectral envelope, but its inverse.offsets are defined using the unit
stonly.
duration:
the
*multiplier can also be used.an offset can be defined in seconds (using unit
s).the absolute duration can be set using
~followed by a value and thesunit.
Note that in v0.2.8, WORLD is making the sounds 1 frame (5 ms) too long if no duration is specified. If you specify the duration, it is generated accurately.
- class vt_server_module_world.Fast2DInterp(x, y, z, ofrv=None, type='linear')
Bases:
objectCreates an interpolant object based on
scipy.interpolate.RectBivariateSplinebut dealing with out of range values.The constructor is:
Fast2DInterp(x, y, z, ofrv=None)wherexandyare 1D arrays andzis a 2D array. The optional argumentofrvdefines the value used for out of range inputs. IfofrvisNone, then the default behaviour ofRectBivariateSplineis kept, i.e. the closest value is returned.Note that the class is not so useful in the end when used with
linear, but is useful if you want to use cubic-splines.- interp(x, y)
- is_in_range(w, r)
- vt_server_module_world.check_arguments(mo, purpose)
Receives an
rematch object from parsing module arguments and do some basic checking.- Parameters:
mo (re.Match) – The argument to parse.
purpose – Purpose is ‘f0’, ‘vtl’ or ‘duration’.
- Returns:
A tuple of the form
(args_ok, args):args_okis True or False depending on whether the argument is fine or not.argscontains a dictionary with the parsed out argument:- v
is the value as a float.
- u
is the unit for offsets, or None for ratios.
- ~
if
True, then it denotes an absolute (average) value instead of an offset.
- vt_server_module_world.parse_arguments(m)
- vt_server_module_world.process_world(in_filename, m, out_filename)
Processes the file in_filename according to parameters m, and stores results in out_filename.
The first step is to analyse the sound file to extract its f0, spectral envelope and aperiodicity map. The results of this operation are cached in a pickle file.
The parameters for this module are:
- Parameters:
f0 – Either an absolute f0 value in Hertz
{### Hz}, a change in semitones{### st}or a ratio{\*###}.vtl – Same for vocal-tract length (only semitones and ratio).
duration – Either an absolute duration in seconds
{~###s}, an offset in seconds{+/-###s}, or a ratio{\*###}.
Just to be clear, these parameters must be keys of the dictionary m.
- vt_server_module_world.regularize_arrays(*args)
Making sure the arrays passed as arguments are in the right format for pyworld.
vt_server_module_vocoder
This module defines the world processor based on vocoder, a MATLAB vocoder designed to be highly programmable.
Here is and example of module instructions:
{
"module": "vocoder",
"fs": 44100,
"analysis_filters": {
"f": { "fmin": 100, "fmax": 8000, "n": 8, "scale": "greenwood" },
"method": { "family": "butterworth", "order": 3, "zero-phase": true }
},
"synthesis_filters": "analysis_filters",
"envelope": {
"method": "low-pass",
"rectify": "half-wave",
"order": 2,
"fc": 160,
"modifiers": "spread"
},
"synthesis": {
"carrier": "sin",
"filter_before": false,
"filter_after": true
}
}
The fs attribute is optional but can be used to speed up processing. The filter definitions that are generated depend on the sampling frequency, so the it has to be known to generate the filters. If the argument is not passed, it will be read from the file that needs processing. Passing the sampling frequency as an attribute will speed things up as we don’t need to open the sound file to check its sampling rate. However, beware that if the fs does not match that of the file, you will get an error.
The other attributes are as follows:
analysis_filters
analysis_filters is a dictionary defining the filterbank used to analyse the input signal. It defines both the cutoff frequencies f and the filtering method.
f Filterbank frequencies
These can either be specified as an array of values, using a predefined setting, or by using a regular method.
If f is a numerical array, the values are used as frequencies in Hertz.
If f is a string, it refers to a predefined setting. The predefined values are: ci24 and hr90k refering to the default map of cochlear implant manufacturers Cochlear and Advanced Bionics, respectively.
Otherwise f is a dictionary with the following items:
- fmin
The starting frequency of the filterbank.
- fmax
The end frequency of the filterbank.
- n
The number of channels.
- scale
[optional] The scale on which the frequencies are divided into channels. Default is log. Possible values are greenwood, log and linear.
- shift
[optional] A shift in millimiters, towards the base. Note that the shift is applied after all other calculations so the fmin and fmax boundaries will not be respected anymore.
Filtering method
A dictionary with the following elements:
- family
The type of filter. At the moment only butterworth is implemented.
For butterworth, the following parameters have to be provided:
- order
The actual order of the filter. Watch out, that this is the order that is actually achieved. Choosing true for zero-phase means only even numbers can be provided.
- zero-phase
Whether a zero-phase filter is being used. If true, then
filtfilt()is used instead offilt().Unlike in the MATLAB version, this is implemented with second-order section filters (
sosfiltfilt()andsosfilt()).
synthesis_filters
It can be the string “analysis_filters” to make them identical to the analysis filters.
This is also what happens if the element is omitted or null.
Otherwise it can be a dictionary similar to analysis_filters. The number of channels has to be the same. If it differs, an error will be returned.
envelope
That specifies how the envelope is extracted.
- method
Can be low-pass or hilbert.
For low-pass, the envelope is extracted with rectification and low-pass filtering. The following parameters are required:
- rectify
The wave rectification method: half-wave or full-wave.
- order
The order of the filter used for envelope extraction. Again, this is the effective order, so only even numbered are accepted because the envelope is extracted with a zero-phase filter.
- fc
The cutoff of the envelope extraction in Hertz. Can be a single value or a value per band. If fewer values than bands are provided, the array is recycled as necessary.
- modifiers
[optional] A (list of) modifier function names that can be applied to envelope matrix. At the moment, only “spread” is implemented. With this modifier, the synthesis filters are used to simulate a spread of excitation on the envelope levels themselves. This is useful when the carrier is a sinewave (see Crew et al., 2012, JASA).
synthesis
The synthesis field describes how the resynthesis should be performed.
- carrier
Can be noise or sin (low-noise and pshc are not implemented).
- filter_before
If true, the carrier is filtered before multiplication with the envelope (default is false).
- filter_after
If true, the modulated carrier is refiltered in the band to suppress sidebands (default is true). Keep in mind that if you filter broadband carriers both before and after modulation you may alter the spectral shape of your signal.
- random_seed
[optional] For noise carriers only.
If the carrier is noise, then a random seed can be provided in random_seed to have frozen noise. If not the random number generator will be initialized with the current clock. Note that for multi-channel audio files, the seed is used for each channel. If no seed is given, the various bands will have different noises as carriers. To have correlated noise across bands, pass in a (random) seed. Also note that the cache system also means that once an output file is generated, it will be served as is rather than re-generated. To generate truely random files, provide a random seed on each request.
If the carrier is sin, the center frequency of each band will be determined based on the scale that is used. If cutoffs are manually provided, the geometric mean is used as center frequency.
- vt_server_module_vocoder.FB_PRESETS = {'ci24': [188, 313, 438, 563, 688, 813, 938, 1063, 1188, 1313, 1563, 1813, 2063, 2313, 2688, 3063, 3563, 4063, 4688, 5313, 6063, 6938, 7938], 'hr90k': [250, 416, 494, 587, 697, 828, 983, 1168, 1387, 1648, 1958, 2326, 2762, 3281, 3898, 4630, 8700]}
Presets for manufacturers’ filterbanks.
- vt_server_module_vocoder.env_hilbert(x)
- vt_server_module_vocoder.env_lowpass(x, rectif, filter, filter_function)
- vt_server_module_vocoder.envelope_modifier_spread(env, m)
- vt_server_module_vocoder.freq2mm(frq)
Converts frequency to millimeters from apex using Greenwood’s formula.
- vt_server_module_vocoder.mm2freq(mm)
Converts millimeters from apex to frequency using Greenwood’s formula.
- vt_server_module_vocoder.parse_arguments(m, in_filename)
Parses arguments for the vocoder module. Unlike some other modules, it is important to know the sampling frequency we will be operating at. The filename can be read from the in_filename or it can be provided to speed-up things. Watchout, though, if the passed fs does not match that of in_filename, you’ll get an error.
- vt_server_module_vocoder.parse_carrier_definition(carrier, synth_fbd)
Parses a carrier definition for the synthesis block.
- vt_server_module_vocoder.parse_envelope_definition(env_def, fs, n_bands)
Parses an envelope definition.
- vt_server_module_vocoder.parse_filterbank_definition(fbd, fs)
Parses a filterbank definition, used for analysis_filters and synthesis_filters.
- vt_server_module_vocoder.parse_filterbank_method(method, freq, fs)
Parses the method part of the filterbank definition and creates the filters based on the freq array and the sampling frequency fs.
- vt_server_module_vocoder.parse_frequency_array(fa)
Parses a frequency array definition as part of a filter bank definition.
- vt_server_module_vocoder.process_vocoder(in_filename, m, out_filename)
The main processing function for the module.
vt_server_module_gibberish
This module contains a function to create a gibberish masker, created out of random sentence chunks, that can be used in the CRM experiment.
{
"module": "gibberish",
"seed": 8,
"files": ["sp1F/cat_8_red.wav", "sp1F/cat_9_black.wav", "..."],
"chunk_dur_min": 0.2,
"chunk_dur_max": 0.7,
"total_dur": 1.2,
"prevent_chunk_overlap": true,
"ramp": 0.05,
"force_nb_channels": 1,
"force_fs": 44100,
"stack": [
{
"module": "world",
"f0": "*2",
"vtl": "-3.8st"
}
]
}
This module is intended to be used at the top of the stack
If the source files have different sampling frequencies, the sampling frequency of the first chunk
will be used as reference, and all the following segments will be resampled to that sampling frequency.
Alternatively, it is possible to specify force_fs to impose a sampling frequency. If force_fs is
0 or None, the default method is used.
A similar mechanism is used for stereo vs. mono files. The number of channels can be imposed with force_nb_channels.
Again, if force_nb_channels is 0 or None, the default method based on the first chunk is used. If the number
of channels of a segment is greater than the number of channels in the output, all channels are averaged and
duplicated to the appropriate number of channels. This is fine for stereo/mono conversion, but keep that in mind
if you ever use files with more channels. If a segment has fewer channels than needed, the extra channels are created
by recycling the existing values. Again, for stero/mono conversion, this is fine, but might not be what you want
for multi-channel audio.
Files
The module will look through the provided files to generate the output. As much as possible, it will try to
not reuse a file, but will recycle the list if necessary.
If the module is first in the stack, the filenames provided in files (or shell_pattern, or re_pattern)
are relative to the folder specified in the file field of the query. Make sure that the folder name ends with a /.
However, note that if the module is not used at the top of the stack, but lower, there may be unexpected results as the folder will be the cache folder of the previous module.
The list will be shuffled randomly based on the seed parameter.
Instead of files, we can have shell_pattern which defines a shell-like patterns as an object:
{
"module": "gibberish",
"seed": 8,
"shell_pattern": {
"include": "sp1F/cat*.wav",
"exclude": ["sp1F/cat_8_*.wav", "sp1F/cat_*_red.wav"]
},
"...": "..."
}
If a list of patterns is provided, the outcome is cumulative.
Alternatively, a regular expression can be used as re_pattern.
If all files, and shell_pattern and/or re_pattern are provided, only one is used by prioritising in the order they are presented here.
Segment properties
chunk_dur_min and chunk_dur_max define the minimum and maximum segment duration. total_dur is the total duration we are aiming to generate. ramp defines the duration of the ramps applied to each segment.
prevent_chunk_overlap defines whether the algorithm tries to select intervals that do not overlap (default is true). This is only relevant if all the sound files have a similar structure (like in the CRM).
Stack
stack is an optional processing stack that will be applied to all the selected files before concatenation.
Seed
The seed parameter is mandatory to make sure cache is managed properly.
- vt_server_module_gibberish.get_file_list_from_array(file_array, folder)
- vt_server_module_gibberish.get_file_list_from_re_pattern(pattern, folder)
- vt_server_module_gibberish.get_file_list_from_shell_pattern(patterns, folder)
- vt_server_module_gibberish.process_gibberish(in_filename, m, out_filename)
vt_server_config
VTServer configuration file management.
- vt_server_config.CONFIG = {'cachefolder': '/var/cache/vt_server', 'cacheformat': 'flac', 'cacheformatoptions': None, 'host': 'localhost', 'logfile': '/var/log/vt_server.log', 'loglevel': 'INFO', 'port': 1996}
The dictionary holding the current configuration (used in other modules). It is instanciated with
read_configuration().
- vt_server_config.find_configuration()
Attempts to find a configuration file in known places:
/usr/local/etc/vt_server,/etc/vt_server,./.
- vt_server_config.read_configuration(config_filename=None)
Reads a configuration file. If none is provided, will try to find one in default places. If that fails or if the config file is invalid will fall back to default options.
vt_server_logging
VTServer logging facilities.
- class vt_server_logging.VTServerLogFormatter
Bases:
Formatter- format(record)
Format the specified record as text.
The record’s attribute dictionary is used as the operand to a string formatting operation which yields the returned string. Before formatting the dictionary, a couple of preparatory steps are carried out. The message attribute of the record is computed using LogRecord.getMessage(). If the formatting string uses the time (as determined by a call to usesTime(), formatTime() is called to format the event time. If there is exception information, it is formatted using formatException() and appended to the message.
- vt_server_logging.get_FileHandler(logfile)
Cache clean-up
The cache can become big and obsolete, so it is a good idea to clean it up regularly. In particular, if the original file does not exist anymore, all the processed files should be removed.
For that, we use the job file that is created by the vt_server_brain.
The job file lists all the files that were created (or used) during a specific job.
If no job file exist for a specific cache file, we erase it. Note, that we may be
missing cache files from individual modules with this approach.
The vt_server_cache module has a command line interface so you can easily
put it in your crontab.
usage: vt_server_cache.py [-h] [-l LEVEL] [-s] [folder]
positional arguments:
folder The cache folder to cleanse. If none is provided, we
will try to read from the default option file.
optional arguments:
-h, --help show this help message and exit
-l LEVEL, --level LEVEL
Level of cleansing [default 0]. 0 will remove all
files created by jobs that are related to files that
do not exist anymore. 1996 will remove *ALL* files
from the cache.
-s, --simulate Will not do anything, but will show what it would do.
The cache cleaning procedure is described below.
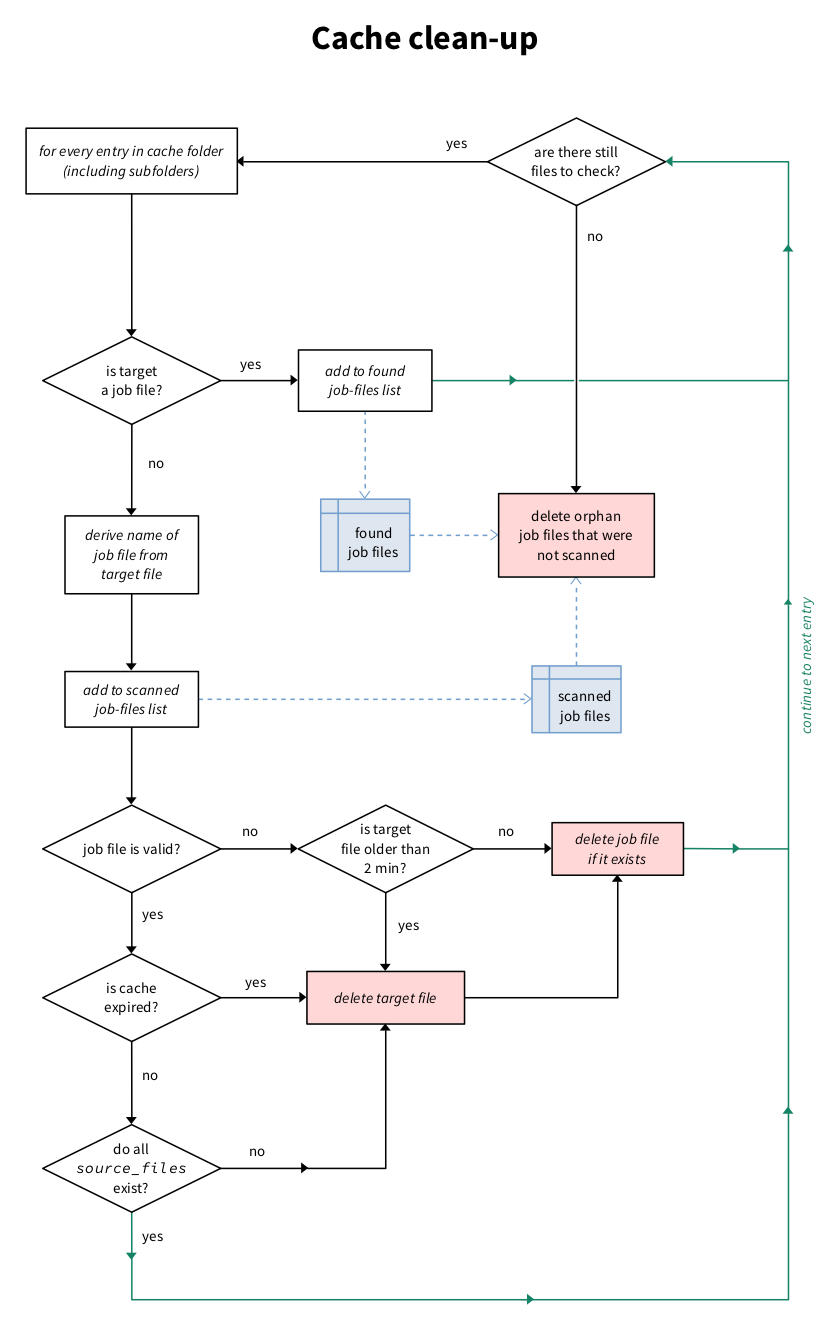
- vt_server_cache.cleanup_cache(fold=None, level=0, simulate=False)
The function that cleans up the cache. The level argument is used to specify how spooky clean you want your cache:
0 is the standard (and default) level, it will scoure the cache folder for generated files. If a file does not have an eponym .job file, it will be deleted. Otherwise, the job file is opened, and, if the original sound file does not exist any more, all files listed as “created” are deleted. The final sound file (or symlinks) created are deleted as well as the job file.
1996 will make your cache spooky clean by eliminating all files (but preserving the directory structure).
- vt_server_cache.delete_file(f, simulate, cache_folder=None, silent=False, indent=0)
- vt_server_cache.spooky_cleanup_cache(fold, simulate, indent=0, cache_folder=None)